
GPT Sonography: Decoding Hand Gestures from Forearm Ultrasound with GPT-4o
Published:
Can a large vision-language model decode hand gestures from forearm ultrasound images without task-specific fine-tuning? In GPT Sonography, we studied this question by framing forearm ultrasound gesture decoding as an in-context learning problem with GPT-4o.
Graphical abstract: Forearm ultrasound images are provided to GPT-4o with text instructions and in-context examples for hand gesture decoding.
Motivation
Forearm ultrasound is a promising sensing modality for human-machine interaction because it can image internal muscle and tendon deformation associated with hand movement. In prior work, ultrasound-based gesture decoding typically required training task-specific machine learning models using labeled ultrasound data.
However, collecting labeled biosignal and medical imaging data can be expensive, subject-dependent, and sensitive to session-to-session variability. Large vision-language models provide a different interface: instead of updating model parameters, they can use task instructions and examples provided directly in the prompt.
The central question of this work was:
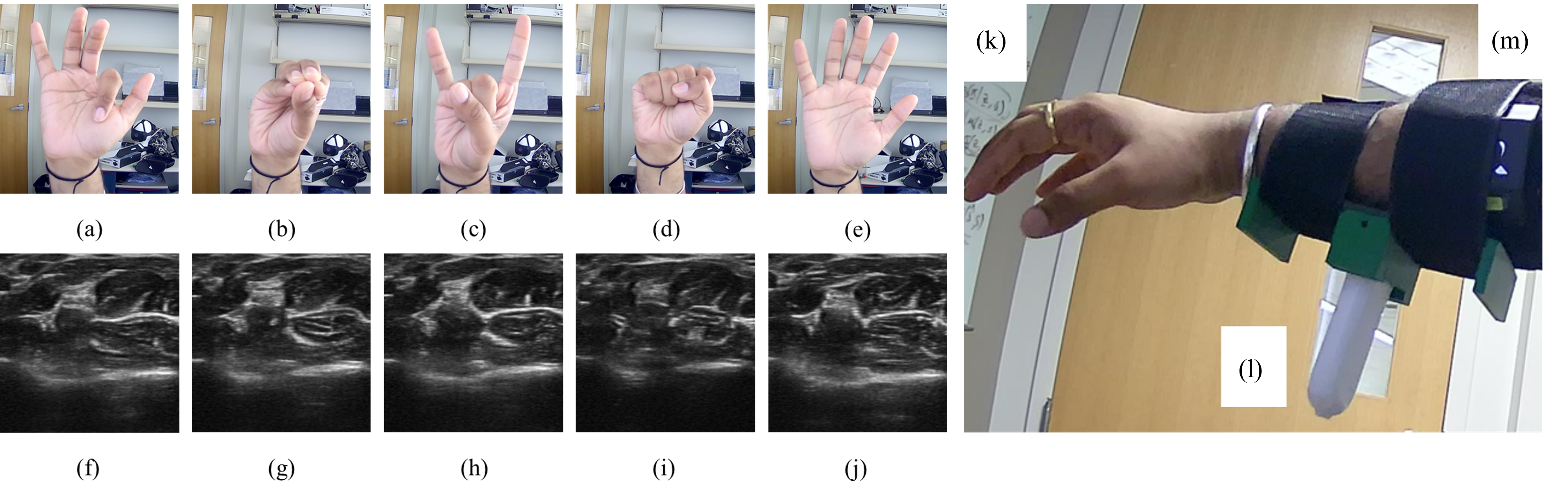
Hand gestures and the corresponding ultrasound images from subject 1. (a) and (f): Index flexion; (b) and (g): all pinch; (c) and (h) hand horns; (d) and (i) fist; (e) and (j): open hand; The probe was strapped to the forearm (k) and enclosed within a 3D printed casing (l), and a strap (m). The visual differences between the ultrasound images are subtle and depend on internal muscle and tendon morphology.
Problem Formulation
Let $D={(x_i,y_i)}_{i=1}^{n}$ denote the labeled forearm ultrasound dataset, where $x_i \in \mathbb{R}^{H \times W}$ is a B-mode ultrasound image and $y_i \in \mathcal{Y}={1,2,\ldots,C}$ is the corresponding gesture label. In this work, $C=5$, corresponding to index flexion, all pinch, hand horns, fist, and open hand.
In a conventional supervised-learning pipeline, one would train an ultrasound-specific classifier $f_\theta$ by minimizing a loss over labeled examples:
\[\theta^\star = \arg\min_{\theta} \sum_{i=1}^{n} \mathcal{L}\left(f_\theta(x_i),y_i\right).\]In GPT Sonography, the LVLM parameters are not fine-tuned. Instead, adaptation happens through the prompt. For a test ultrasound image $x_t$, we construct a prompt containing a task instruction, optional labeled in-context examples, and the test image:
\[\mathcal{P}(x_t) = \left( \text{instruction}, \mathcal{E}, x_t \right),\]where $\mathcal{E}\subset D$ is the set of labeled examples inserted into the prompt. The LVLM then predicts the gesture label directly from this prompt:
\[\hat{y}_t = \operatorname{LVLM}\left(\mathcal{P}(x_t)\right).\]Thus, the key difference is that conventional supervised learning adapts by updating $\theta$, whereas in-context learning adapts by changing the examples and instructions provided in $\mathcal{P}(x_t)$.
Zero-Shot and Few-Shot ICL
We evaluated zero-shot and few-shot prompting. In the zero-shot setting, the example set is empty:
\[\mathcal{E}_0=\varnothing,\]so the prompt contains only the task instruction and the test image $x_t$.
In the $q$-shot setting, the prompt contains $q$ labeled examples per gesture class. The in-context example set can be written as
\[\mathcal{E}_q = \left\{ (x_{c,r},c) : c\in\mathcal{Y}, \ r=1,\ldots,q \right\},\]where $q\in{1,2,3}$ is the number of examples per class. Since there are $C=5$ gesture classes, the prompt contains $qC$ labeled ultrasound examples in total.
The corresponding prompt is
\[\mathcal{P}_q(x_t) = \left( \text{instruction}, \mathcal{E}_q, x_t \right),\]and the predicted class is
\[\hat{y}_t = \operatorname{LVLM}\left(\mathcal{P}_q(x_t)\right).\]Retrieval-Augmented In-Context Learning
A key component of the method was retrieval-augmented in-context learning. Instead of selecting in-context examples randomly or from a fixed split, we retrieve examples that are visually similar to the test ultrasound image and insert them into the prompt.
Following the paper, let $\hat{x}_t$ denote the flattened vector representation of the test image $x_t$, and let $\hat{x}_i$ denote the flattened vector representation of a candidate labeled image $x_i\in D$. The similarity between the test image and a candidate image is computed using cosine similarity:
\[\operatorname{sim}(\hat{x}_t,\hat{x}_i) = \frac{ \hat{x}_t \cdot \hat{x}_i }{ \lVert \hat{x}_t \rVert \, \lVert \hat{x}_i \rVert }.\]The retrieved example set is then defined as the $K$ highest-scoring labeled examples from $D$:
\[\mathcal{N}_K(x_t) = \operatorname{top\text{-}K}_{(x_i,y_i)\in D} \operatorname{sim}(\hat{x}_t,\hat{x}_i).\]Here, $\mathcal{N}_K(x_t)\subset D$ is the set of retrieved image-label pairs used as in-context examples for the test image $x_t$. The RAG-ICL prompt is therefore
\[\mathcal{P}^{\mathrm{RAG}}_K(x_t) = \left( \text{instruction}, \mathcal{N}_K(x_t), x_t \right),\]and the LVLM prediction is
\[\hat{y}_t = \operatorname{LVLM} \left( \mathcal{P}^{\mathrm{RAG}}_K(x_t) \right).\]This retrieval step was especially effective in within-session experiments, where retrieved ultrasound frames can be visually close to the test image because of stable probe placement and acquisition conditions. However, this result should be interpreted carefully: in frame-based ultrasound classification, high local similarity between retrieved examples and the test image can produce near-ceiling within-session performance, while cross-session testing remains more challenging.
Results
Within-session accuracy improved from 19.3% in the zero-shot setting to 74.0% with 2-shot in-context learning. In the within-session setting, the examples and test samples are acquired close together, with relatively stable probe placement and acquisition conditions. This makes retrieval especially effective, but it can also produce highly similar support examples.
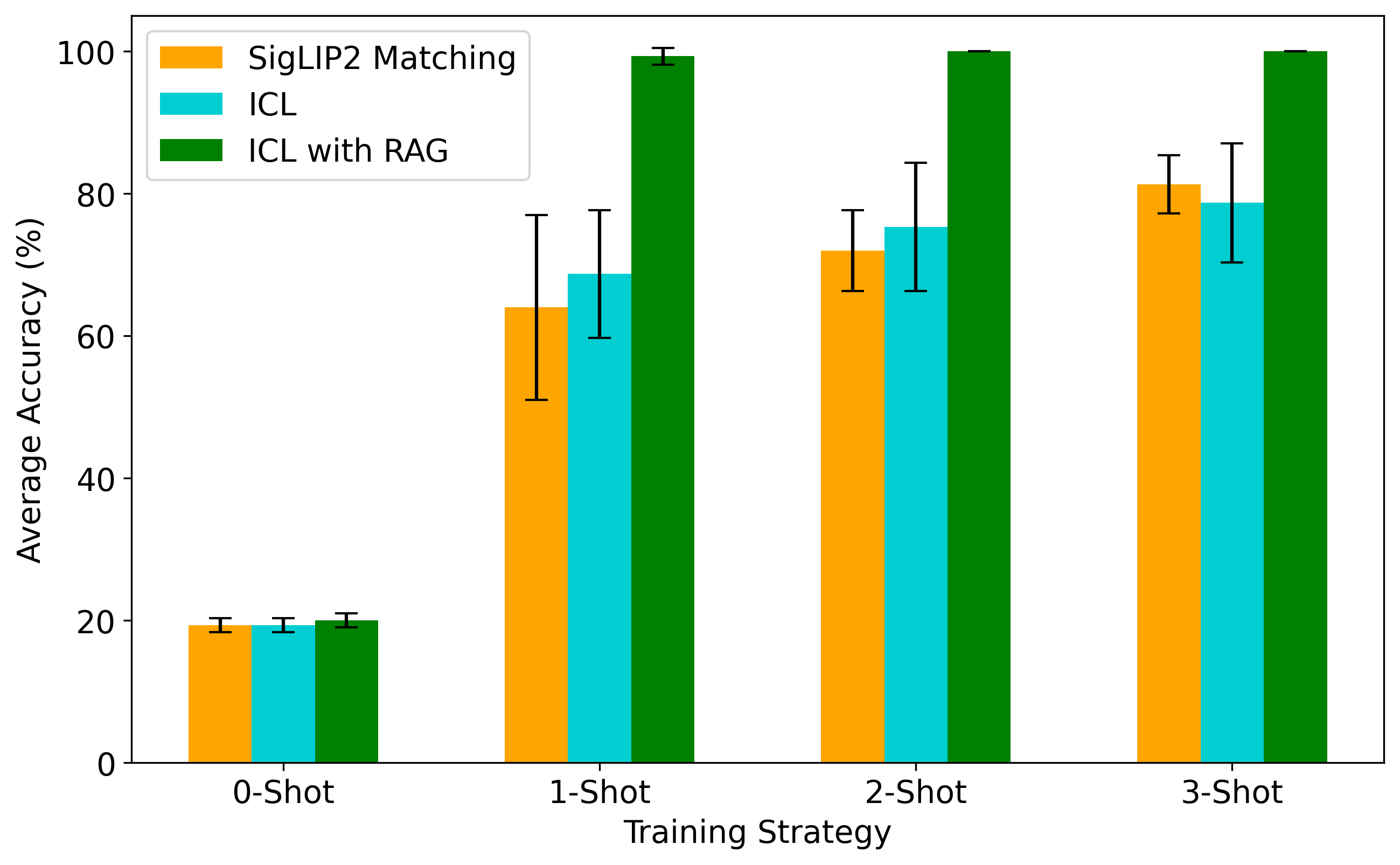
Within-session results. Retrieval-augmented ICL reached near-ceiling accuracy and outperformed both standard ICL and matching-network baselines using SigLIP2 similarity.
Cross-session accuracy improved from 20.0% in the zero-shot setting to 61.3% with 3-shot in-context learning. In the cross-session setting, the test samples come from a later session, making the task more representative of session-to-session variability.
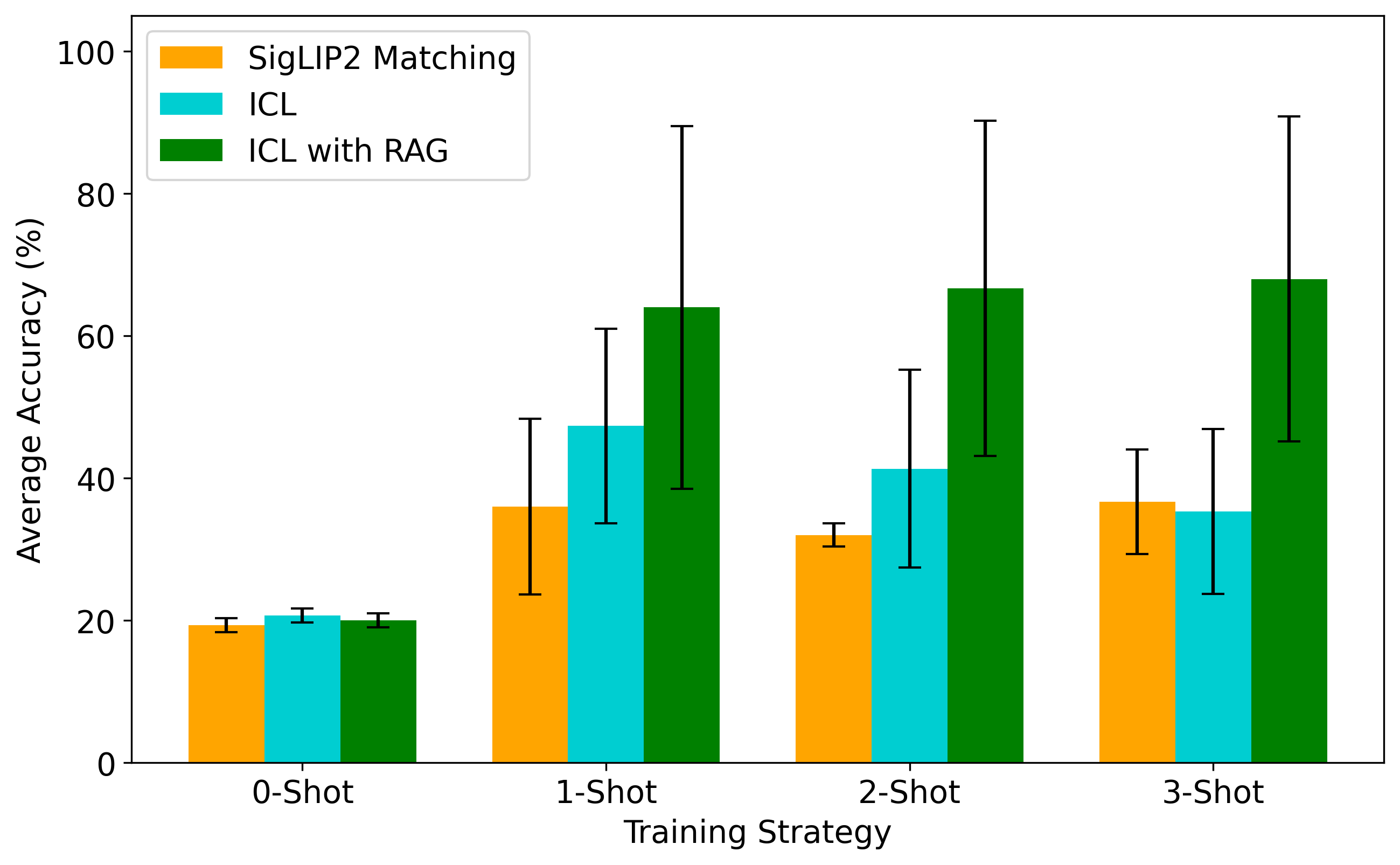
Cross-session results. Performance was lower and more variable than within-session testing, but retrieval-augmented ICL still provided the strongest overall trend across few-shot settings.
Interpretation
The main result is that zero-shot GPT-4o performed near chance on this specialized ultrasound task, but performance improved substantially when labeled examples were provided in context.
This suggests that the LVLM should not be interpreted as a pretrained ultrasound gesture expert. Rather, it can act as a flexible visual reasoning model that uses task instructions and example-based context to perform a specialized classification task.
The key distinction is the adaptation mechanism. Conventional supervised learning adapts through parameter updates:
\[\theta^\star = \arg\min_{\theta} \sum_i \mathcal{L}(f_\theta(x_i), y_i).\]In-context learning adapts through the prompt:
\[\hat{y} = \operatorname{LVLM} \left( \text{instructions}, \text{examples}, x_{\text{test}} \right).\]Implications for biosensing, medical imaging and human-machine interfacing
For biosignal and medical imaging problems, full fine-tuning can be difficult because datasets are often small, labels are expensive, and performance can vary across subjects, sessions, and sensor placements.
This work does not suggest that LVLMs replace task-specific ultrasound models today. Instead, it shows that ICL may provide a useful complementary approach for specialized sensing problems where rapid adaptation and data efficiency are important.
For forearm ultrasound-based human-machine interfacing, this is especially relevant because the sensing problem is highly subject- and session-dependent. A prompt-based interface could allow future systems to adapt using a small number of representative examples rather than requiring a full model retraining pipeline.
Connection to my PhD work
This journal article extends our NeurIPS 2024 AIM-FM workshop paper and is also part of my PhD thesis on biosignal-based deep learning for human-machine interfacing, robotic teleoperation, and control.
Across my PhD work, I studied how forearm ultrasound can be used to estimate hand gestures, hand pose, and force-related information. GPT Sonography explores a newer question within that broader direction: whether foundation models can provide a lightweight interface for decoding specialized biosignal images without conventional fine-tuning.
Citation
@article{bimbraw2026gptsonography,
title={GPT Sonography: Hand Gesture Decoding From Forearm Ultrasound Images via a Large Vision-Language Model},
author={Bimbraw, Keshav and Wang, Ye and Liu, Jing and Koike-Akino, Toshiaki},
journal={IEEE Access},
year={2026},
doi={10.1109/ACCESS.2026.3687477}
}
Note
This post is intended as a soft introduction to the work rather than a complete technical treatment. The full paper contains more detailed experiments, ablations, comparisons, and discussion on prompting strategies, retrieval-augmented in-context learning, and the challenges of interpreting ultrasound frame-based classification results.
Please refer to the paper for the complete methodology and results. If you have questions or would like to discuss the work, feel free to reach out. The experimental design and discussion around LVLMs for specialized biosignal imaging tasks are especially interesting.
Acknowledgment
I am grateful to Toshiaki Koike-Akino, Jing Liu, and Ye Wang for their guidance and mentorship during my internship at Mitsubishi Electric Research Laboratories (MERL) in Summer 2024. I especially want to thank Toshi for his persistence, encouragement, and thoughtful guidance in helping bring this work through to the final journal publication.